2019年中国人工智能行业市场分析:面临“卡脖子”困窘,呼吁三方协力实现真正智能
中国人工智能发展面临“卡脖子”窘境
五一前上海召开的院士沙龙活动中“徐匡迪之问”引发共鸣:“中国有多少数学家投入到人工智能的基础算法研究中?”核心算法缺位,人工智能发展面临“卡脖子”窘境。中国制造正从“硬件组装厂”向“软件组装厂”蔓延,政产学研浮躁如故、积习难改。
中国有多少数学家投入到人工智能的基础算法研究中?:凤毛麟角
五一前上海召开院士沙龙活动,中国工程院院士徐匡迪等多位院士的发问引发业界共鸣,被称为“徐匡迪之问”。这一对当下中国人工智能直击核心的提问,不但表明了当下中国人工智能发展的短板,同时也揭去了披在当下所谓“人工智能”算法外表华丽的面纱。
“我国人工智能领域真正搞算法的科学家凤毛麟角。”4月28日超声大数据与人工智能应用与推广大会,东南大学生物科学与医学工程学院教授万遂人表示,“徐匡迪之问”直击我国人工智能发展的核心关键问题,“如果这种情况不改变,我国人工智能应用很难走向深入、也很难获得重大成果”。
人工智能是计算机技术发展到高级阶段,融合了数学、统计学、概率、逻辑、伦理等多学科于一身的复杂系统。是当下所有信息技术所不能达到的高级应用。其最为核心的技术便是人工智能算法。如何让计算机能像人类一样进行思考,如同人一样利用现有的知识进行学习并实现合乎逻辑的推理,是人工智能算法试图实现的目标。其技术绝不是一般公司能够轻轻松松实现的。当下国际社会公认的人工智能研发顶尖公司,如Google和IBM等投入了海量资源,动用了顶尖的数学科学家、计算机专家,能实现了计算机程序的一定程度智能化,但距离真正的AI仍然相差很远。
进入2018年,中国人工智能产业“忽如一夜春风来,千树万树梨花开”,一下子出现了无数人工智能研发公司,并都号称到得了显著技术进步。比如基于人工智能的医学图像识别系统,对于某个疾病的识别率高达95%以上,远远高于人工判读。中国人工智能真实如此繁荣吗?
未来中国人工智能市场规模将超700亿
中国部分新兴技术领域已经进入全球第一梯队,从人工智能产业看,中国人工智能领域融资金额居全球之首,达到325亿美元,在全球占比达到58%。
据前瞻产业研究院发布的《中国人工智能行业市场前瞻与投资战略规划分析报告》统计数据显示,2015中国人工智能市场规模已突破100亿元,到了2016年中国人工智能市场规模达到141.9亿元,同比增长26.3%。截止到2017年中国人工智能市场规模增长至216.9亿元,同比增长52.8%。初步测算2018年中国人工智能市场规模将达339亿元左右,比2017年增长56.3%,远高于全球17%的增速水平。并预测在2019、2020年中国人工智能市场规模将达500亿元、710亿元。2015-2020年复合年均增长率为44.5%。
2015-2020年中国人工智能市场规模统计及增长情况预测
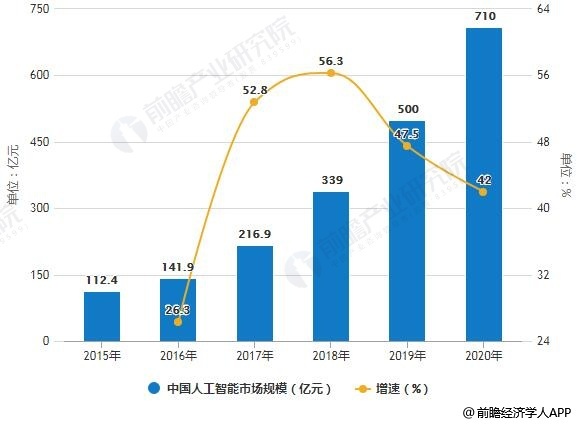
数据来源:前瞻产业研究院整理
1、中国人工智能产业界研发现状分析
某业内人士有幸了解过国内某大型互联网企业制作的人工智能应用。其定位于利用AI程序判读CT图像,利用算法实现对病灶的判读,提高医生的效率并降低负担。
当问到其核心的人工智能算法的时候,企业倒也是直言不讳,其核心技术是使用了国际上开源的人工智能算法。在被引入后进行针对特定目的进行了二次开发,并最后整体打包成为一套完整的人工智能应用。正是因为使用了开源的人工智能算法,才出现了许多应用明显能力不足的情况。
比如其无法提供一套大一统的应用。公司一共向我们展了大约六种疾病的诊断应用。不同的疾病需要使用对应的AI程序才可以得出相对准确的结果。如果将A疾病的算法使用到B疾病上,完全无法正常工作。就我浅薄的理解,真正人工智能的算法并不应当如些。它应当是一套通用的算法,既可以用于A疾病的诊断,同样也可以用于B疾病。我们需要做的是提供大量疾病案例供AI学习训练,随着训练样本数量的增加,会使人工智能模型被训练的越来越准确。但是这种一个疾病一个AI的方式还是头一次听说。好比一个医生只能看男性长胡子的感冒患者,如果是个不没长胡子的男患者,只能去隔壁就医了。
浙江大学应用数学研究所所长孔德兴教授清清楚楚说明白了这个问题。因为公司使用的都是开源算法。开源人工智能算法能力是不足的,根本无法实现预期的能力。人工智能算法堪称信息行业的核武器。如此威力庞大的算法怎么样可会在网上被开源出来?可以认为开源的人工智能算法相当于玩具水平的东西。想借助这种低水平的算法,来实现真正的人工智能应用怎么可能实现呢?
开源算法唯一好处在于人人都可获得,门槛非常低。所以大量公司从网上下载了开源算法,然后以其为核心研发出一套AI应用,再披上华丽的面纱,唬的普通用户奉若神明。这也在突然间中国出现了如此多的人工智能公司的原因之一吧。
真正人工智能的到来还需要很长时间,绝不是借助网上共享了的代码就能够实现的,必须要脚踏实地,一步一个脚印地开发出来,不付出努力想投机取巧是万万不能的。我国依靠开源代码和算法是否足够支撑人工智能产业发展?为什么要有自己的底层框架和核心算法?
2、缺少核心算法,会被“卡脖子”
“如果缺少核心算法,当碰到关键性问题时,还是会被人‘卡脖子’。”浙江大学应用数学研究所所长孔德兴教授对科技日报记者表示,我国人工智能产业的创新能力并没有传说中的那样强,事实是,产业发展过度依赖开源代码和现有数学模型,真正属于中国自己的东西并不多。
4个月零基础学会人工智能、16讲入门人工智能、算法线下大课……类似培训在网络上非常火爆,通过对于现有算法、模型的学习和训练,成长为人工智能工程师的“短平快”可见一斑。
既然代码是开源的,拿来用就好,为什么还有可能被“卡脖子”?
孔德兴解释,开源代码是可以拿过来使用,但专业性、针对性不够,效果往往不能满足具体任务的实际要求。以图像识别为例,用开源代码开发出的AI即使可以准确识别人脸,但在对医学影像的识别上却难以达到临床要求。“例如对肝脏病灶的识别,由于边界模糊、对比度低、器官黏连甚至重叠等困难,用开源代码很难做到精准识别。在三维重构、可视化等方面难以做到精准反应真实的解剖信息,甚至会出现误导等问题,这在医学应用上是‘致命’的。”
“碰到专业性高的研究任务,一旦被‘卡脖子’将会是非常被动的,所以一定要有自己的算法。”孔德兴说。换句话说,是否掌握核心代码将决定未来的AI“智力大比拼”中是否拥有胜算。用开源代码“调教”出的AI顶多是个“常人”,而要帮助AI成长为“细分领域专家”,需以数学为基础的原始核心模型、代码和框架创新。秦陇纪总结,中国制造正从“硬件组装厂”向“软件组装厂”蔓延,浮躁如故。
3、有算法之“根”才能撑起产业“繁茂”
所谓“树大根深”,人工智能的发展也是同样道理,越在底层深深扎下根基,越能够发展出强大的产业。那么,借助开源代码,“半路出家”的AI产业为什么会难以为继?
孔德兴解释说,在获得同样数据的前提下,以开源代码运行,AI深度学习之后或许能输出结果,但由于训练框架固定、算法限制,当用户进行具体的实际应用时,将很难达到所期望的结果,而且难以修改、完善、优化算法。
“如果从底层算法做起,那么整个数学模型、整个算法设计、整个模拟训练‘一脉相承’,不仅可以协同优化,而且可以根据需求随时修改,从而真正解决实际问题。”孔德兴说,基础算法往往是指研究共性问题的算法,它涉及到基础数学理论、高性能数值计算等学科,可以应用到多种实际问题中;而针对性强的应用算法往往会应用到具体问题所涉及的“具体知识、先验信息”,从而更好地解决实际应用问题。
“基础算法和应用算法都很重要,拥有基础算法将更有助于应用算法的丰富与深入。”孔德兴说,AI要应对的现实生活是复杂、多变的,当能够“应对自如”时,才能够促成产业的“繁茂”。
4、呼吁三方协力让数学不再置身事外
一方面是政策引导,其实国家已经在加大这方面的扶持,例如科研基金上的设置等。”针对如何解决“徐匡迪之问”反映出来的问题,孔德兴认为,
第二方面是行业企业在进行科技创新时,应有意识将数学学者纳入进来。“如果通过算法的开发,最终产品落地了,企业应该将算法开发时的数学学者纳入到成果分享中来。”孔德兴说,社会目前对于数学科学等“软实力”的认可程度不足,行业或法规层面应该做好数学研究成果的产权保护工作。
第三方面,数学家本身应该积极参与到人工智能发展的浪潮里。”孔德兴呼吁,AI的未来发展需要数学家深度参与。由于目前仍处于“弱人工智能”时代(可以说是数据智能时代),AI的实现主要是依赖计算机的巨大算力和巨大的存储能力,底层算法的问题或许并不突出,但在未来的发展,AI将可能融入逻辑、思维等智慧的内容,这些都需要数学科学的原始创新,有大量的基础问题亟待数学家攻克。
算法的进阶一定是来源于“原创者”,而不是“跟随者”。孔德兴说:“实际上深度学习的应用已遇到了天花板,我们需要新的数学技术(如部分依赖逻辑、部分依赖数据的‘聪明算法’),让计算机变得聪明起来。这些工作都需要数学家的参与。”
5、人工智能发展陷入了拿来主义怪圈
历史已经证明,通过购买现成的产品与技术来实现技术的跨越,在科学技术领域是行不通的。中国科技行业的哪一样,不都是经历了艰苦奋斗,无数科学家默默无闻为之奉献后,方才得以傲视世界群雄?比如中国的量子技术,比如中国的国防科技,中国的天宫空间站,中国的嫦娥月球车。
作为技术高度密集的人工智能技术,其商业领域竟然是陷入了拿来主义,着实让人意外。中国AI产业大约从2018年开始一夜爆红,稍微有些规模的IT厂家无不宣称,已经推出人工智能产品到市场上。当时认为这也是中国科学人多年来的厚积薄发,技术积累到一定程度后实现了产业的繁荣。可惜的当徐匡迪院士发出直击灵魂的提问后,才发现原来中国的AI产业不过是看上去很美丽。
人工智能技术本质上是以数学算法为核心,辅以计算机技术的产品。与其说是一个IT产品,倒不如说是一套数学理论,如随机森林算法,贝叶斯算法等都是复杂的数学、统计学、概率领域的内容。这些算法试图通过数字概率来描述人类思考的过程。计算机技术不过是通过编程语言在信息系统中实现算法过程。可见推动人工智能前进的必定是数学领域的专家,而不是IT部门的人才。
大数据方面,2015年我国大数据产业规模已达2800亿元。截止至2017年我国大数据产业规模增长至4700亿,同比增长是30.6%。初步测算2018年我国大数据产业规模达到5400亿元左右,同比增长15%。预测在2020年我国大数据产业规模将突破万亿元。然而,综合国内外环境、新兴技术发展等多种因素,大数据产业的增速出现了下滑。我国的大数据产业也面临着从高速发展向高质量发展的关键转型期。
2015-2020年我国大数据产业规模统计情况及预测
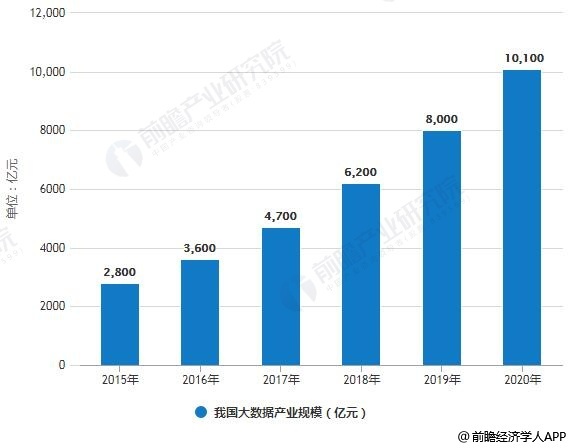
数据来源:前瞻产业研究院整理
基础学科,比如数学一直是我们非常薄弱的环节。当华罗庚将中国数学推向一个高峰后,之后众人还只是在努力追赶国际同行,一直没有能在国际上独领风骚。可想而知在人工智能商业、民用领域,我们的进展同国际同行相经差距明显。所以2018年的AI产业大爆发就让人心生怀疑。
没有安心研发,那么就拿现成的好了。正巧大家可以从网上下载到开源人工智能算法。于是大家都将其下载下来,加上漂亮的外壳,让我们的AI产品炫酷夺目。如果有机会能探究当下较火的商业人工智能产品,最终会发现所有算法都指向了同一个来源。不是说开源不好,正如浙江大学孔德兴教授所言,开源的产品是由其它国家人开发出来的,无论其功能好与坏,你并不知道它的开发思路是怎么样的。算法高效之处不知为何,而其能力不足之处也茫然不知。尽管其是开放源代码的,不知道有多少IT公司认认真真地研读一遍将其吃透研究明白了。
还有一点想跟大家讨论的是,开源的人工智能算法绝不会是高效的,或者说是真正的算法程度。开源代码是IT高手们将自己想法实现并放到网上供大家讨论的东西,往往是初级的,探索性的东西。据说当现开源AI代码是从印度工程师放出来的(这点也是听闻,不确定)。现在大家应当有所体会,人工智能绝不会是一两个工程师就可以搞出来的东西,要不为什么谷歌公司投入了那么多人力物力才实现了将国际象棋冠军打败的程度。而这套算法却无法应对英国高中数学问题。还有一点,真正尖端的人工智能算法,永远不会出现在互联网上供人们共享的。
资本的力量是可怕的。为了赚取利润占领市场,商家秉持着唯快不破的想法,极速将产品推出来,哪有功夫去管它是好是坏呢。可是人工智能是一门科学,是最为严谨的数学课题,不可能容得下这般不负责任的炒作。
这个世界是公平的,你怎样对待科学,这就会怎样对待你。玩弄科学,炒作概念,不脚踏实地的钻研反而投机取巧,必定会被其反噬。如果大家一直在追踪AI发展情况,其实已经可以感受到,似乎AI的热度较去年有所下降。而到现在为止尚未有一个真正能拿出手的商业人工智能产品在市场上出现。这已经说明许多。
爱之深恨之切。我们都期盼着中国IT有朝一日能够站在世界巅峰。这个过程是需要脚踏实地的,一个台阶一个台阶攀登上去,没有任何取巧的办法。亡羊补牢未为晚也,希望徐匡迪之问能惊醒中国IT公司,扎扎实实的一步一个脚印的走下去,让国人早日用上真正的人工智能应用。


广告、内容合作请点这里:寻求合作
咨询·服务