2019年全球大数据行业市场现状与发展趋势 Kafka和Spark成为主流应用【组图】
大数据具有四大特性
大数据(big data),是指需要通过快速获取、处理、分析以从中提取价值的海量、多样化的交易数据、交互数据与传感数据,其规模往往达到了PB(1024TB)级。不同机构对大数据也有不同的定义。
麦肯锡对大数据的定义:一种规模大到在获取、存储、管理、分析方面大大超出了传统数据库软件工具能力范围的数据集合,具有海量的数据规模、快速的数据流转、多样的数据类型和价值密度低四大特征。
移动信息化研究中心对大数据的定义:大数据是帮助企业利用海量数据资产,实时、精确地洞察未知逻辑领域的动态变化,并快速重塑业务流程、组织和行业的新兴数据管理技术。
IDC认为大数据具备海量(volume)、异构(Variety)、高速(Velocity)和价值(Value)四大特性。

全球大数据储量规模爆发式增长
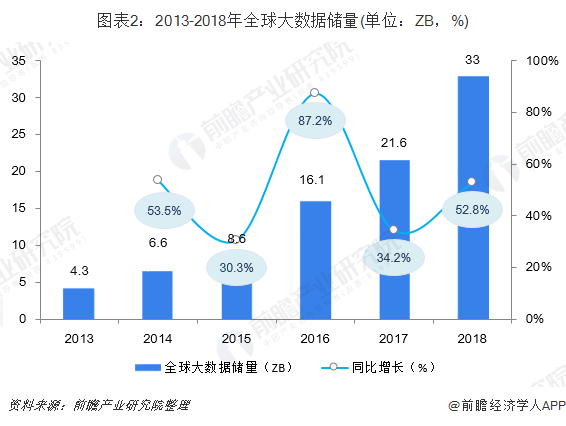
随着物联网、电子商务、社会化网络的快速发展,全球大数据储量迅猛增长,成为大数据产业发展的基础。根据国际数据公司(IDC)的监测数据显示,2013年全球大数据储量为4.3ZB(相当于47.24亿个1TB容量的移动硬盘),2018年全球大数据储量达到33.0ZB,同比增长52.8%。
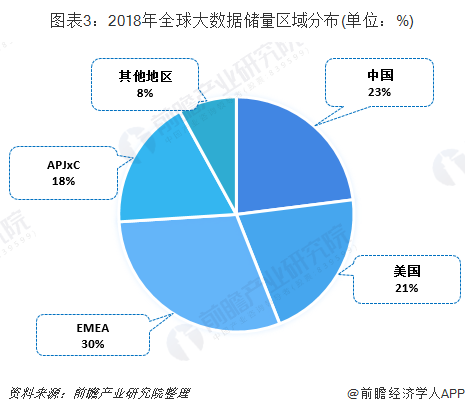
从大数据储量分布情况来看,美国大数据储量占比为21%,EMEA(欧洲、中东、非洲)占比为30%,中国地区占比为23%。
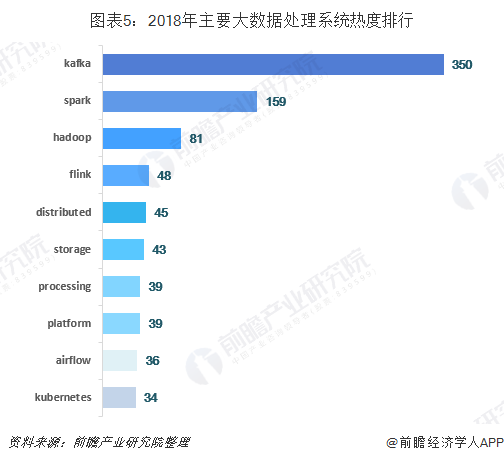
流式处理占主导地位,Kafka和Spark成为主流应用
根据数据处理的时效性,大数据处理系统可以分为批式(batch)大数据和流式(streaming)大数据两类。其中,批式大数据又被称为历史大数据,流式大数据又被称为实时大数据。
以Hadoop为代表的批处理大数据系统需先将数据汇聚成批,经批量预处理后加载至分析型数据仓库中,以进行高性能实时查询。这类系统虽然可对完整大数据集实现高效的即席查询,但无法查询到最新的实时数据,存在数据迟滞高等问题。
以Spark Streaming、Storm、Flink为代表的流处理大数据系统将实时数据通过流处理,逐条加载至高性能内存数据库中进行查询。此类系统可以对最新实时数据实现高效预设分析处理模型的查询,数据迟滞低。
随着互联网、计算机行业快速发展,企业对数据的时效性越发重视,企业应用也逐渐由批处理数据平台向实时的流数据数据平台转移。以流数据处理为代表的Spark、kafka大数据系统近年来大放异彩,取代了Hadoop的主导地位。

以上数据来源参考前瞻产业研究院发布的《中国大数据产业发展前景与投资战略规划分析报告》。
更多深度行业分析尽在【前瞻经济学人APP】,还可以与500+经济学家/资深行业研究员交流互动。



本文作者信息
李明俊(前瞻产业研究员、 分析师)
邀请演讲广告、内容合作请点这里:寻求合作
咨询·服务